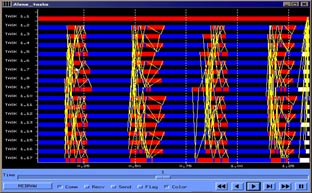
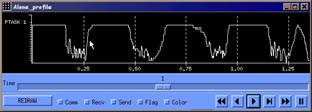
One of the major interests in developing Dimemas was to analyze different processor scheduling policies when several applications/tasks are mapped to the same set of processors. The most common policies have been included: FCFS, Round Robin, Fixed priorities, Unix-like, boost priorities… For each of them several parameters can be selected: time cost of context switch, how to modify priorities in any situation, how long to perform a busy wait for a message prior to plan a context switch… Figure 18 and Figure 19 corresponds to FFT benchmark. The first one shows the Gantt diagram of the application, marking in dark blue computation time and in red blocking time. White color, and the end of the graph, stands for task finalization. Each task has been mapped to a different processor, and the simulation parameters are 4 MB/s network bandwidth and 50 microseconds latency. Total execution time is close to 1.35 seconds. The second one is the profile of the execution, providing information of the number of tasks running simultaneously. In the communication area (communications are the yellow lines), the profile graph decrease down to 4, meaning that there are only running 4 tasks in parallel, because most are blocked due message late arrival.
 |
 |
 |
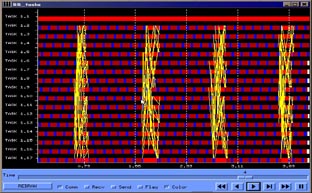 Four tasks per processor |
 |
 |
 |
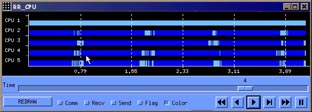 |
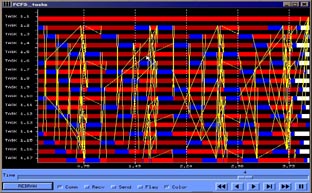
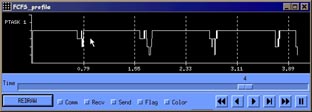
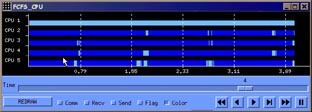
Figures 20, 21 and 22 correspond also to FFT benchmark, but each processor is performing the work of four tasks (except task one, having a dedicated processor). Processor scheduling is FCFS, blocking the task only when trying to get a message not available. The total application time now is 3.92 seconds. Figure 7 is the information of tasks execution, with the new color (dark red) standing for waiting for resources (processor). Time waiting for resources become important as a tasks frees the processor when blocking for a message, and request it again when the message is received.
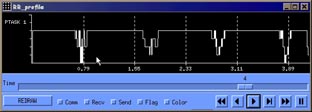
Figures 23, 24 and 25 are representations of the same benchmark, with a four to one mapping, but using Round Robin as processor scheduling policy. Total execution time is nearly identical to FCFS, but time-sharing is quite different. Quantum time for RR has been set to 1 miliseconds. Further analysis can be performed modifying context switch time, quantum, or using different scheduling policies.
Distributed file system
The second extension to Dimemas had provided the opportunity to analyze different file system implementations. Dimemas tracefiles have been extended to read new records containing information related to file system: open, read, write, close, unlink…
PAFS is the file system proposed in comparison to xFS (NOW project, Berkeley University).
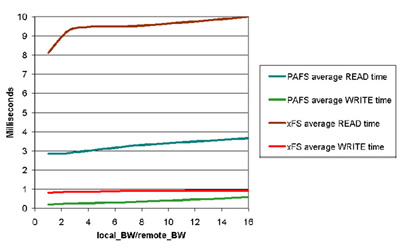
Figure 26 presents the influence of network bandwidth on average read/write time. In this figure, bandwidth is presented as a ratio between local bandwidth (the bandwidth within a node) and the remote bandwidth (the bandwidth of the interconnection network). For example, 1 means network access as fast as memory access.
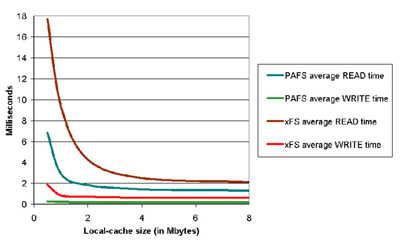
Another possible analysis is presented in Figure 27, where the influence in the local cache size related to the cost of a single file operation is analyzed.