Dimemas history starts in 1993, having ideas from the European Esprit project Supernode II. One of the Supernode II goals was to implement a kernel in a transputers base machine (distributed memory), where it was possible to execute concurrently several applications sharing the processors. The first intention for Dimemas is being able to predict the behavior of the application in the standalone system, but using a simple communication model.
Next step was to predict the behavior of several applications while sharing processors. Transputers incorporates two basic process scheduling algorithms: FCFS and Round Robin, but it may happen that new ones produce better results.
Using the bases of Dimemas, a single communication model and resource management, further academic research has been performed, including processor scheduling, distributed file system and shared memory.
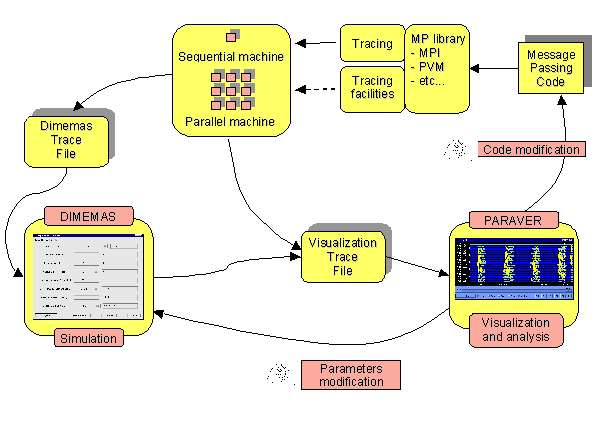
Figure 1 represents how Dimemas can be used and the benefits of using the Dimemas environment for application analysis, development and tuning. These benefits are based in the possibility of not using a parallel machine to run the application to get the traces and the possibility to analyze different application choices without changing neither rerunning the application itself.
The tracefile records the CPU time in between communications and the communications primitives, thus tracefile does not contain any contention due to network contention. With these records Dimemas will rebuild the application behavior, using the tracefile and the architectural parameters defined using a GUI. Per process CPU time is used as opposed to elapsed time. In this way, if a process suffers preemption during the instrumentation, Dimemas will not consider the preempted time and the predicted performance will approximate what would happen in a dedicated machine. The advantages and disadvantages of this mechanism follow:
- Cost reduction: By using Dimemas, the need to perform runs on a dedicated parallel machine is minimized, and a single workstation can be used to obtain the traces.
- Analysis of non-existent machines: Analysis of application execution in non-existing machines performed using the architectural parameters and the traces obtained in the workstation.
- Quality of performance prediction: Although the instrumentation, the model and the parameters are not ideal, the quality of the prediction is really good taking into account the cost savings.
- Performance: Application development cycle is reduced, because a single workstation is used, and it is always available.
The loop involving Dimemas and Paraver, the simulator and the visualization tool, is the second benefit on using this environment. The user has the chance to analyze the application behavior when some parameters are changed, for example, what will happen to application execution time is the execution time of a given function is reduced in 50%? In the output information section, some examples describe the different possible analysis.



